Production ML Case Study
Production Multistage Multimodal Recommender on Amazon Elastic Kubernetes Service (EKS)
Built and deployed an end-to-end recommender system with candidate generation, ranking, reranking, filtering, feature caching, and Triton serving on Kubernetes.
Why This Design
The target use case is an ecommerce homepage recommender that serves both registered users and anonymous visitors. Recommendations need to account for request context such as device type, time of day, and day of week, while still producing reasonable cold-start results for users with little or no history.
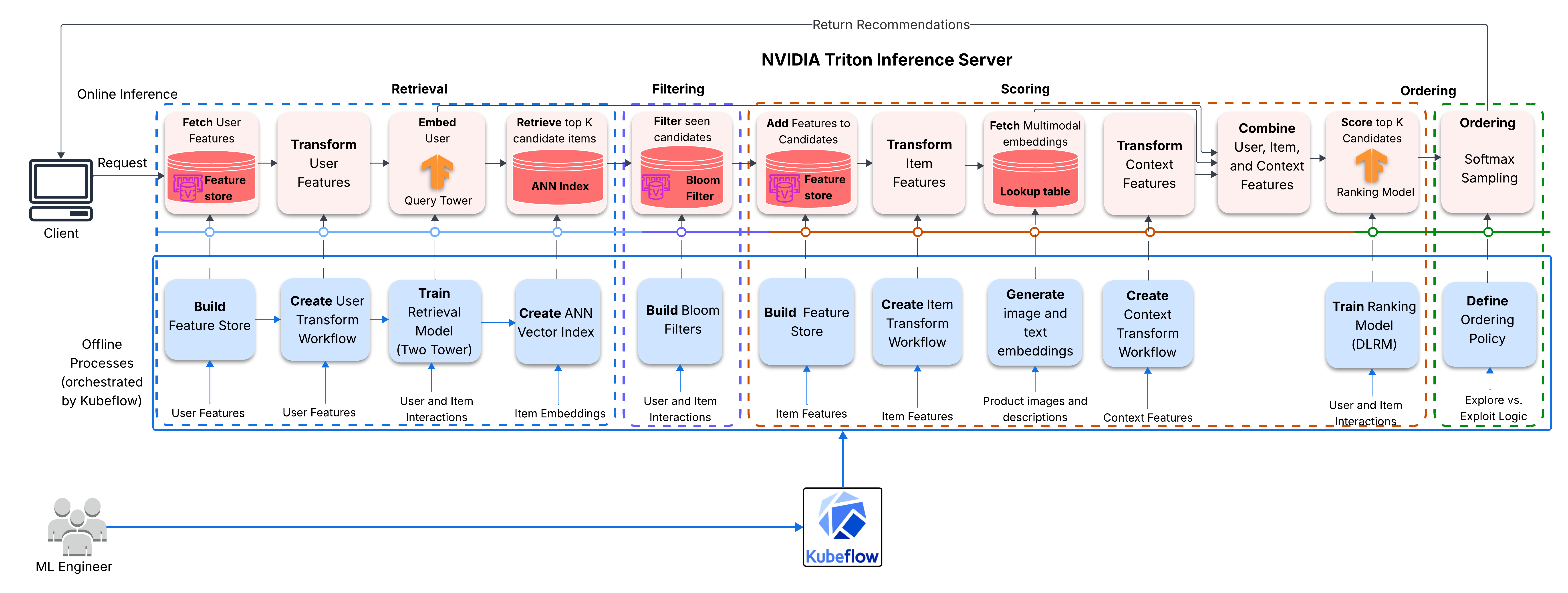
The system also has to scale to large product catalogs. Scoring millions of items on every request is impractical, so the architecture uses a multistage design: a lightweight retrieval stage quickly narrows the candidate set, then a heavier ranking stage scores the smaller pool.
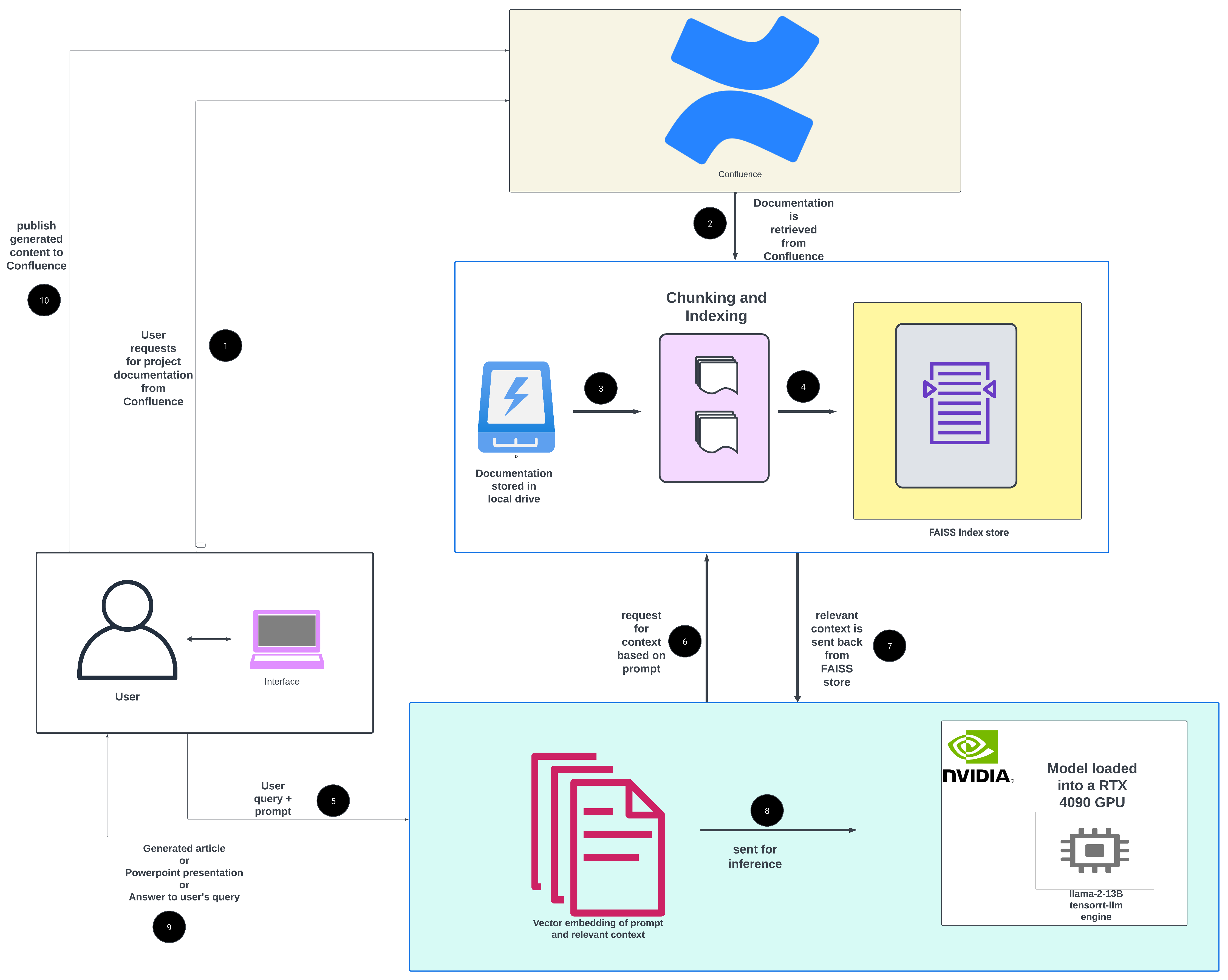
To keep the system current without rebuilding the full retrieval stack every day, I separated the workflow into an initial Kubeflow pipeline and an incremental fine-tuning pipeline. The initial pipeline builds preprocessing workflows, trains models from scratch, creates the ANN index, and deploys Triton. The incremental pipeline updates the query tower and ranker with new interactions while keeping item embeddings fixed.
System summary
- Two-Tower candidate generation, Seen-items filtering, DLRM ranking, score-based Diversity reranking.
- A feature masking technique allows the Two-Tower to learn dedicated "starting" embeddings for unknown users.
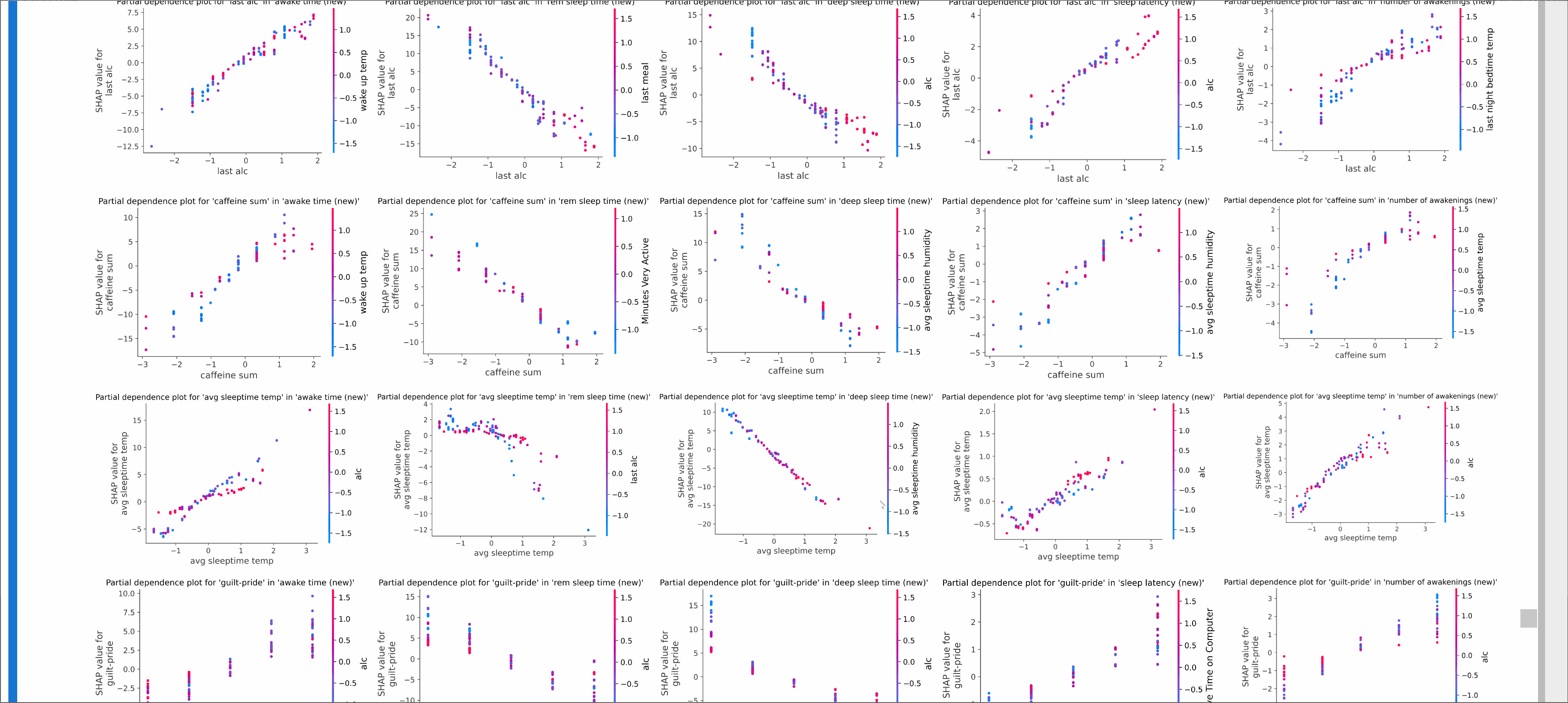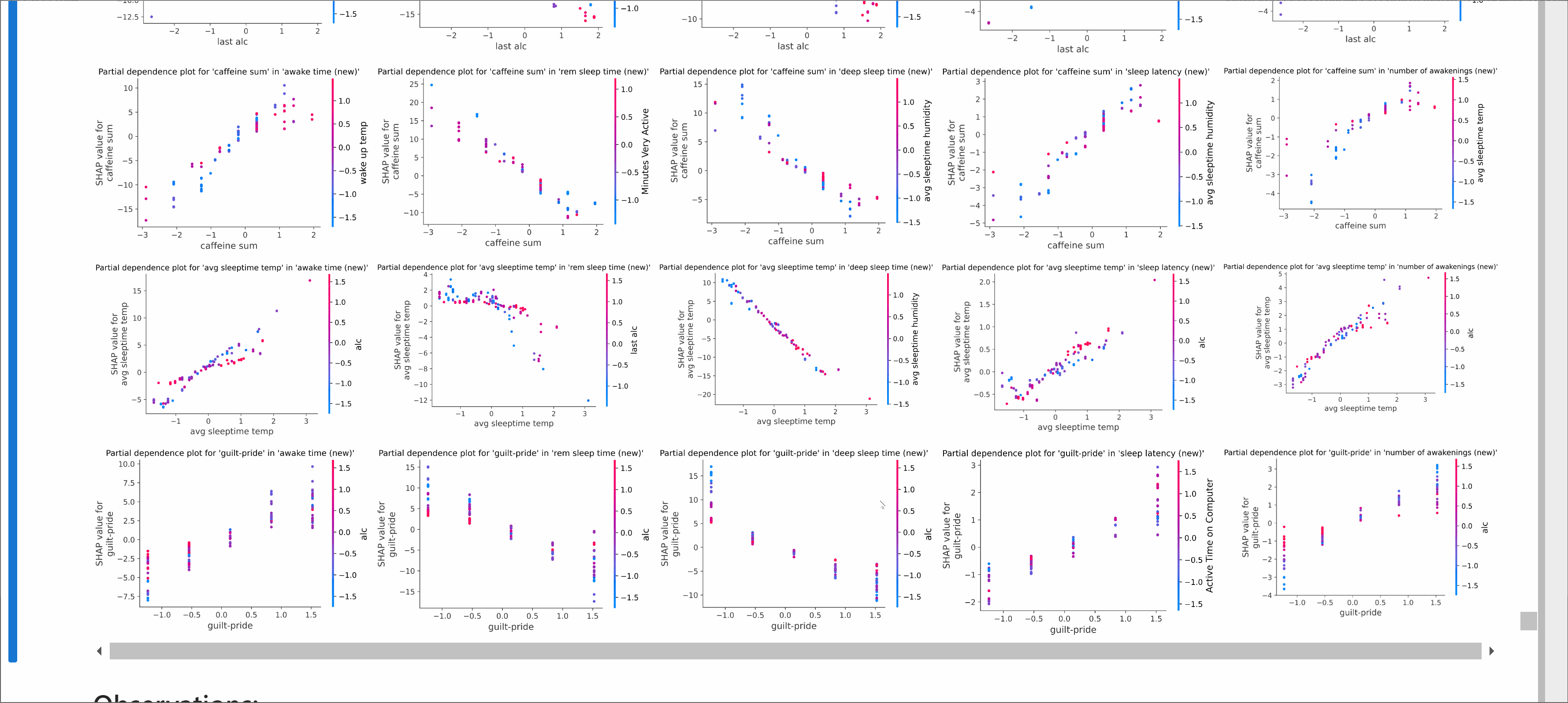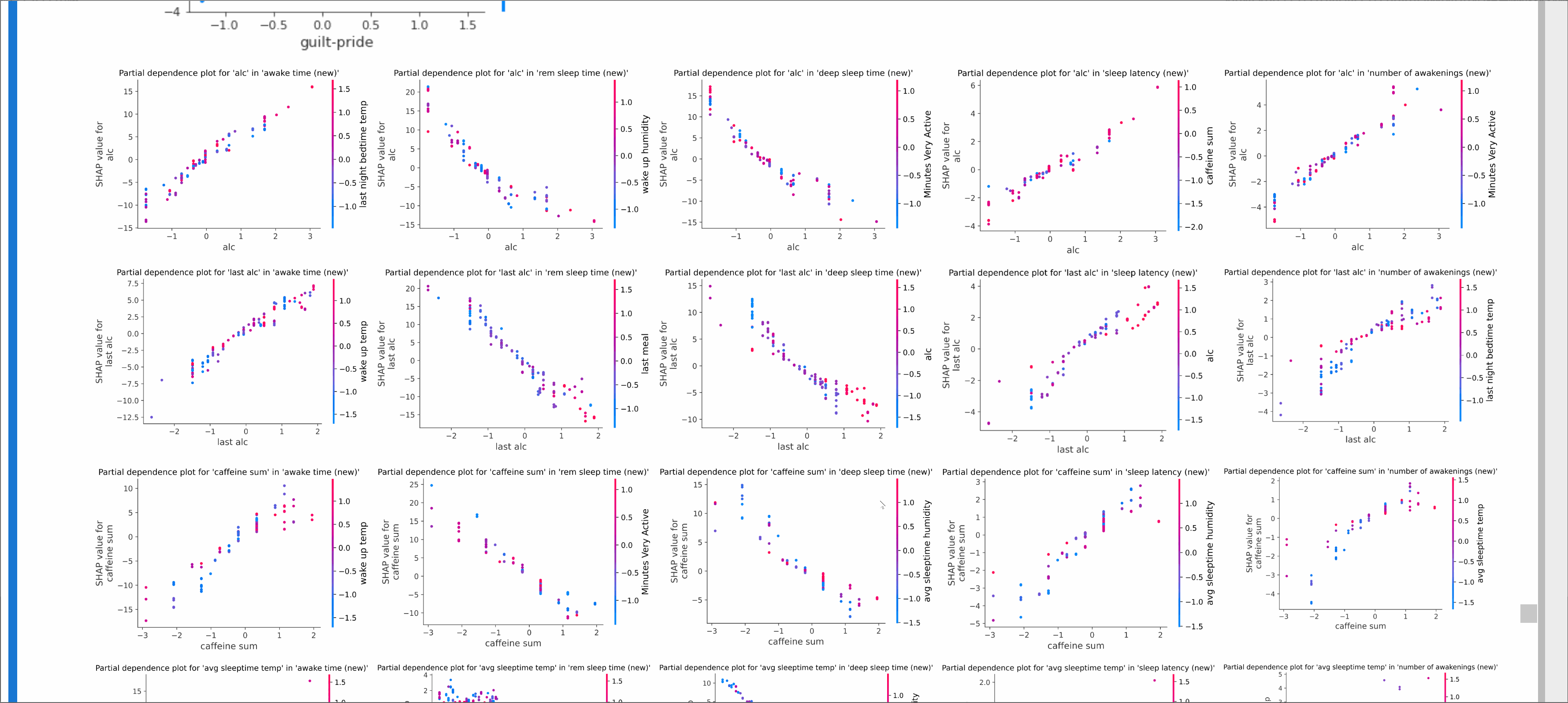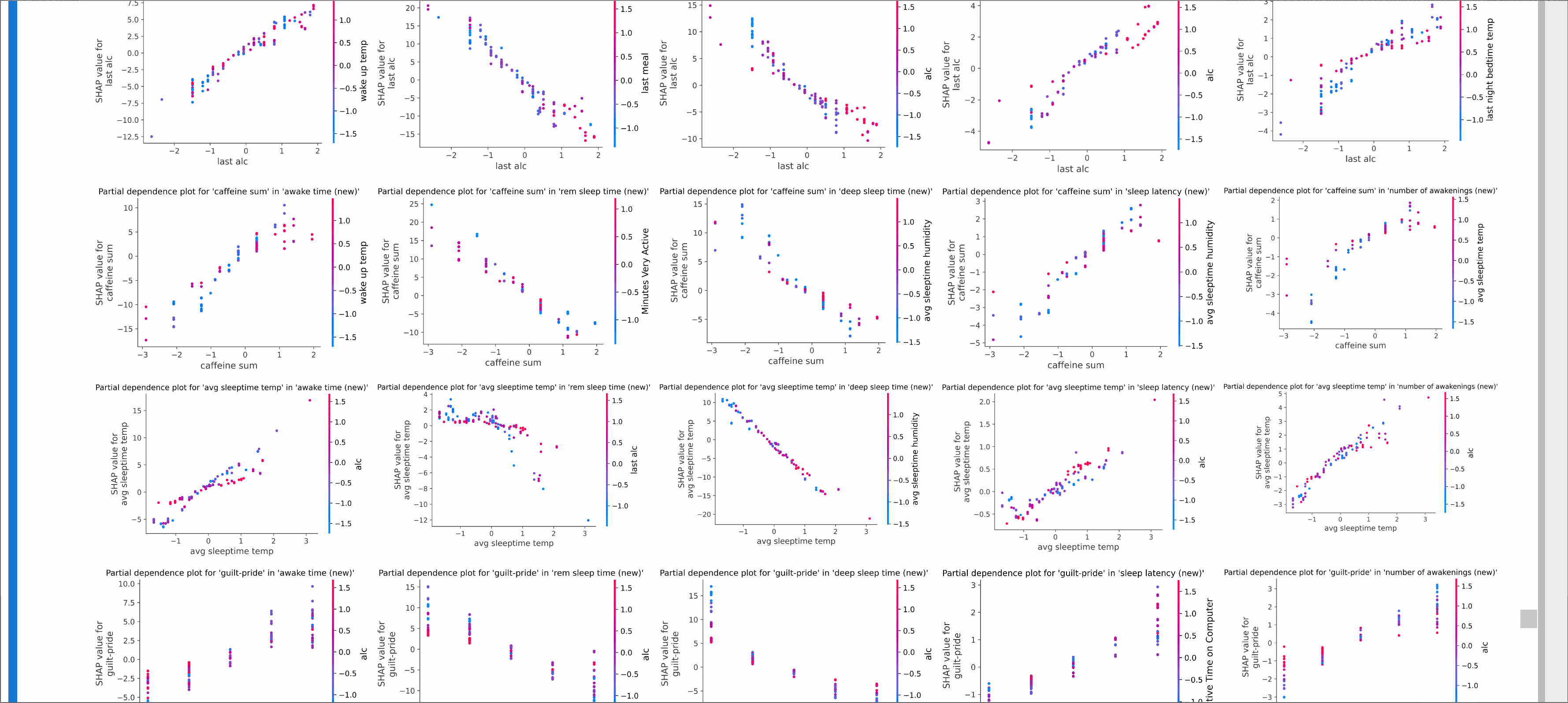
- Context-aware ranking based on device type and timestamp enables adaptation of recommendations to the current request context
- Real-time user feature updates allows the system to adapt to changing user intent in near real-time.
- Multimodal learning with CLIP-image and Sentence-BERT embeddings improves item cold-start performance and overall recommendation quality.
- Bloom filters are used to exclude items that have already been seen by the user.
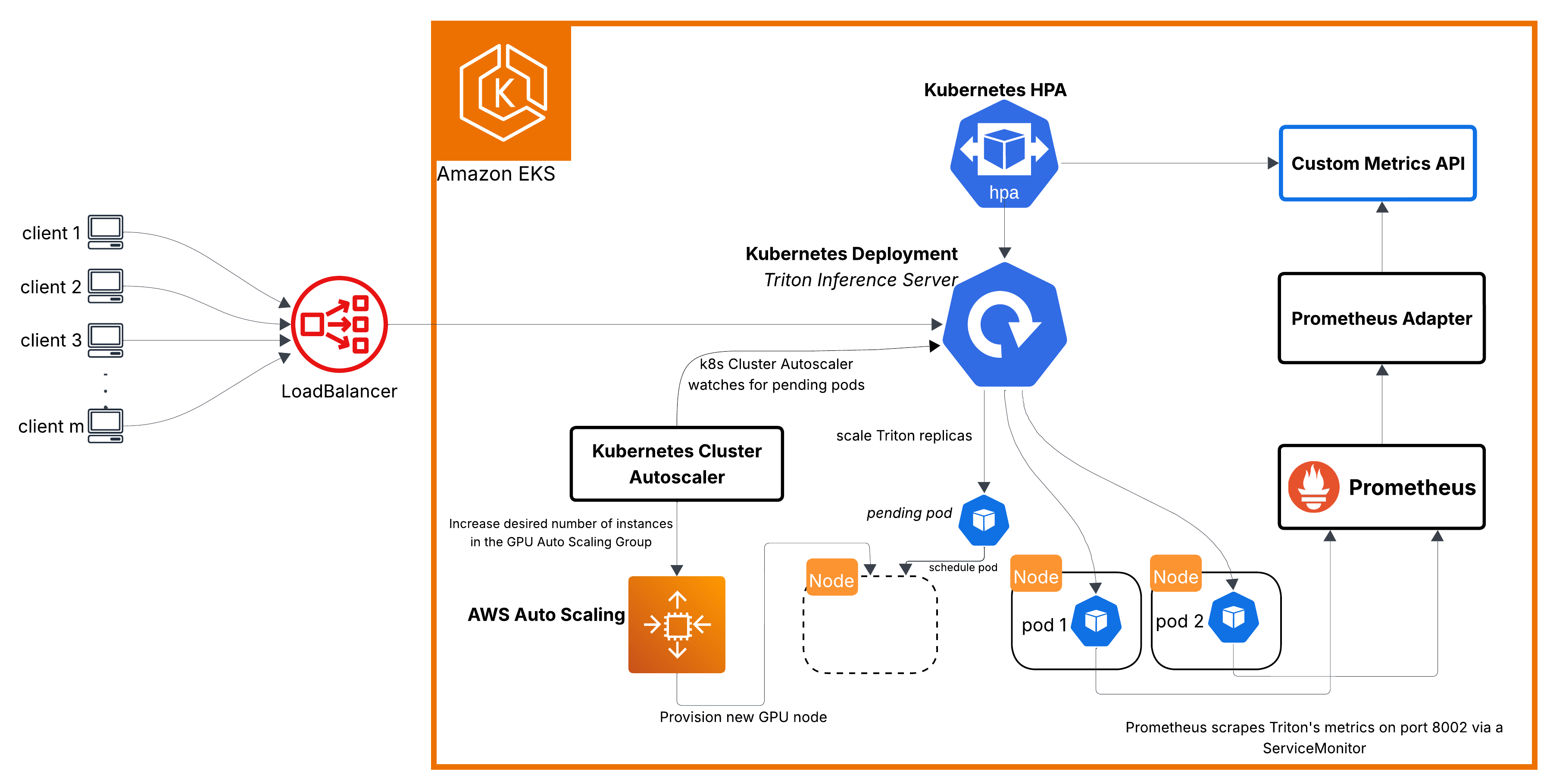
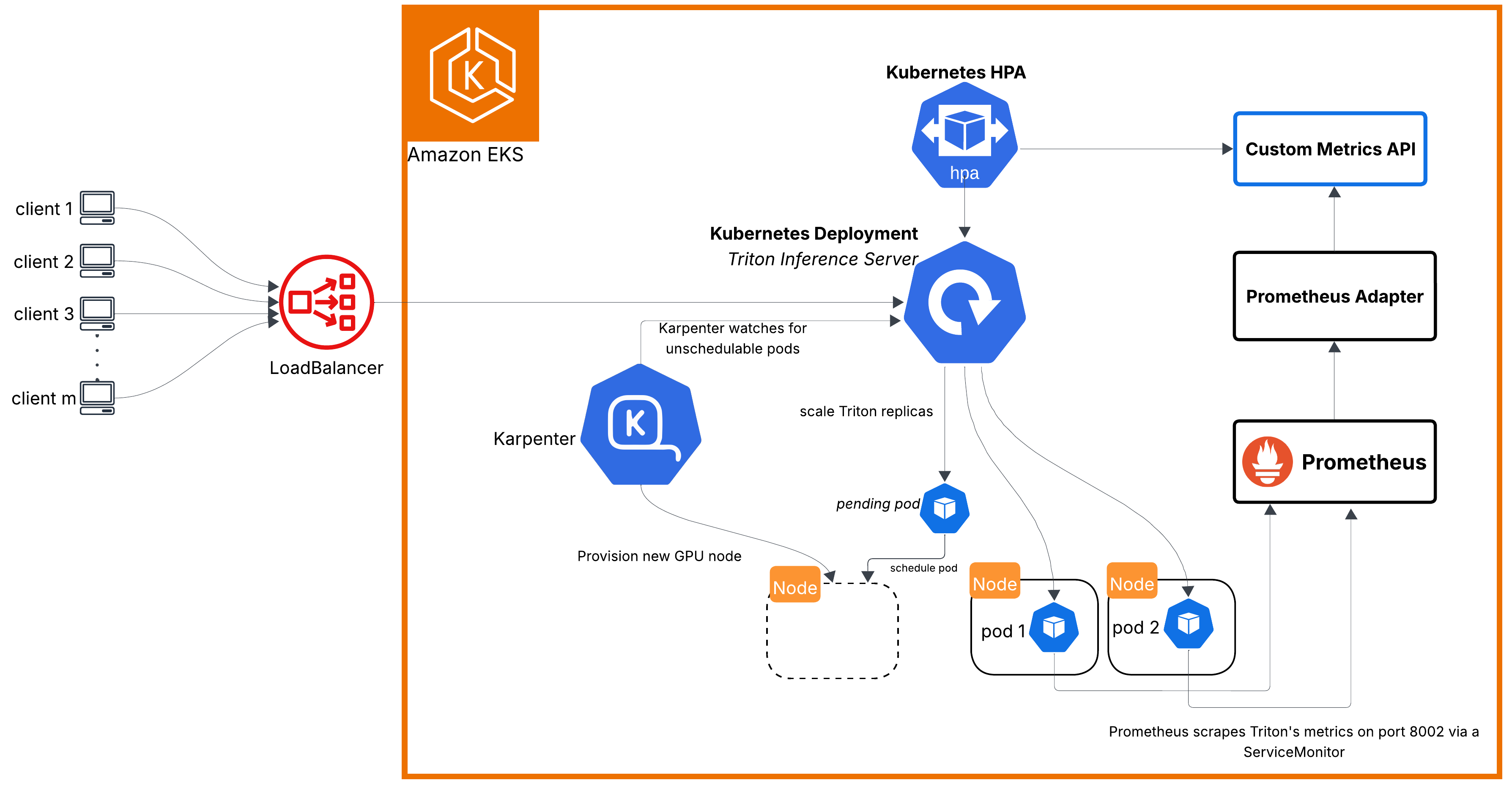
- Infrastructure is autoscaled with Kubernetes Horizontal Pod Autoscaler (HPA) and Karpenter
- Serving stack includes Amazon EKS, NVIDIA Triton Inference Server, TensorFlow, Feast feature stores (Offline backed by S3 and Athena, Online backed by Valkey (Redis)), ANN index (FAISS), Kubeflow pipelines, and Valkey-backed Bloom filters.
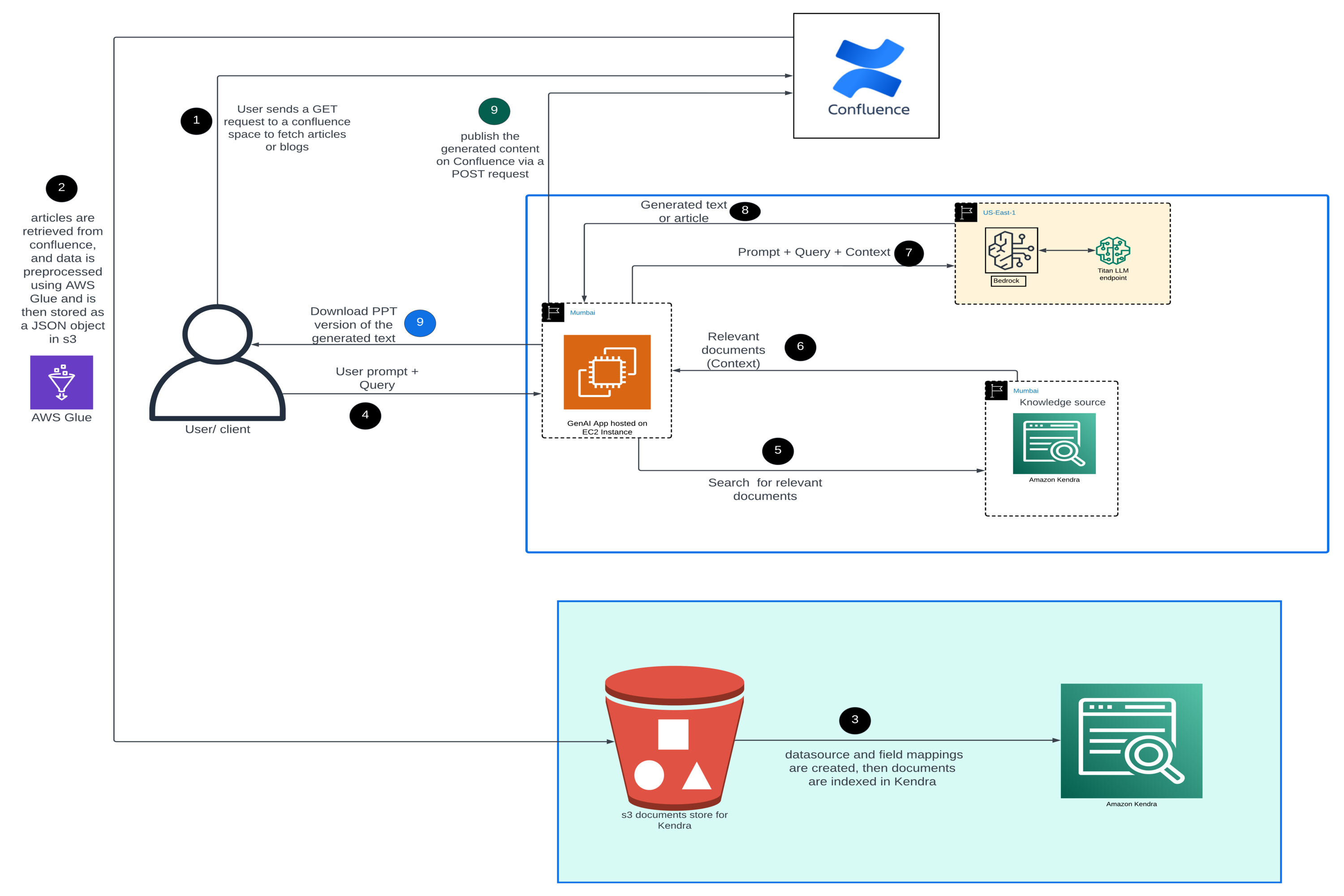
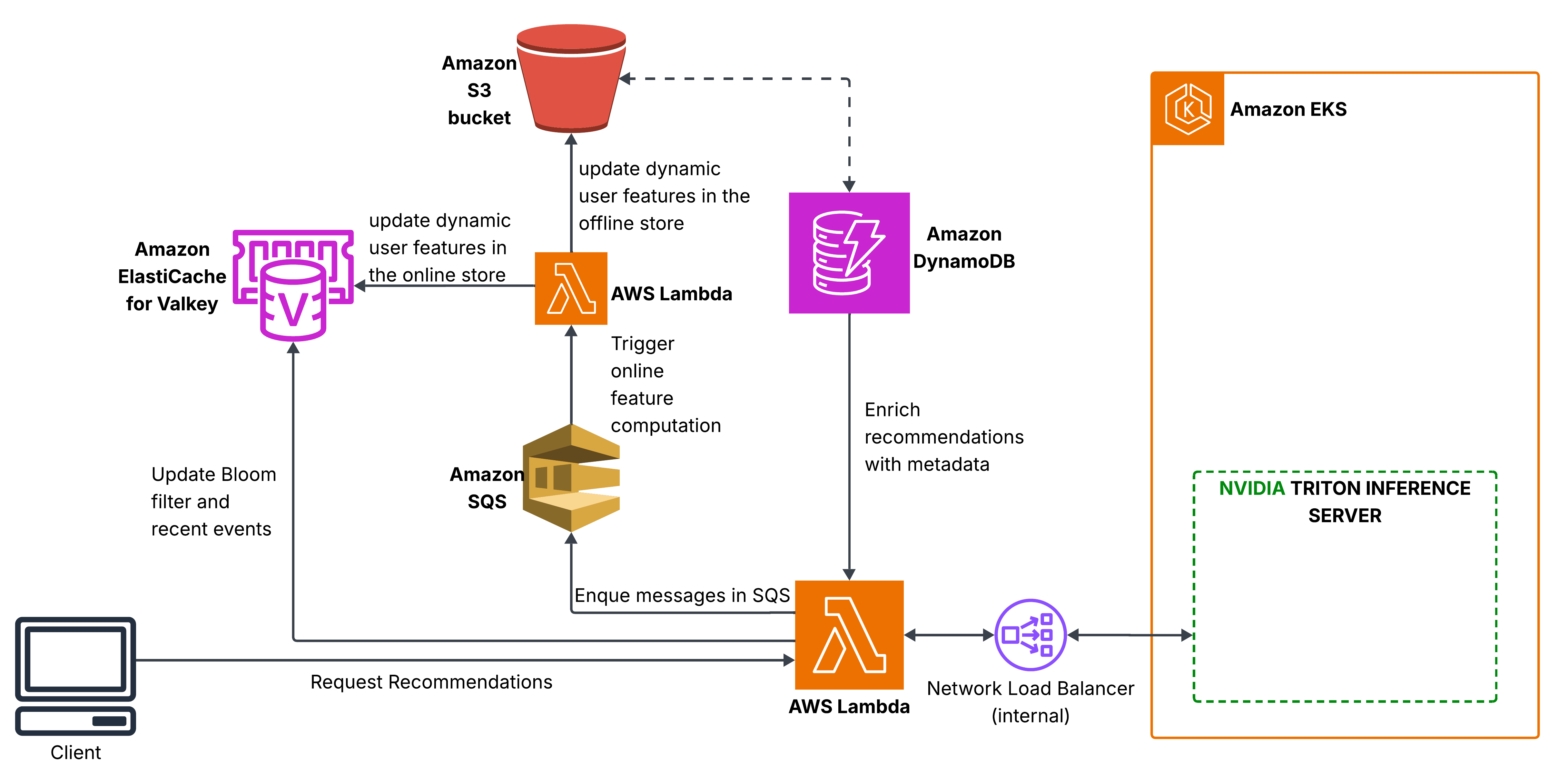
Online Feature Updates
Recommendation requests and feature updates run through separate Lambda functions in the same VPC as ElastiCache and the EKS node subnets hosting Triton. Triton is exposed through an internal AWS Network Load Balancer, while DynamoDB, S3, and SQS are reached privately through VPC endpoints.
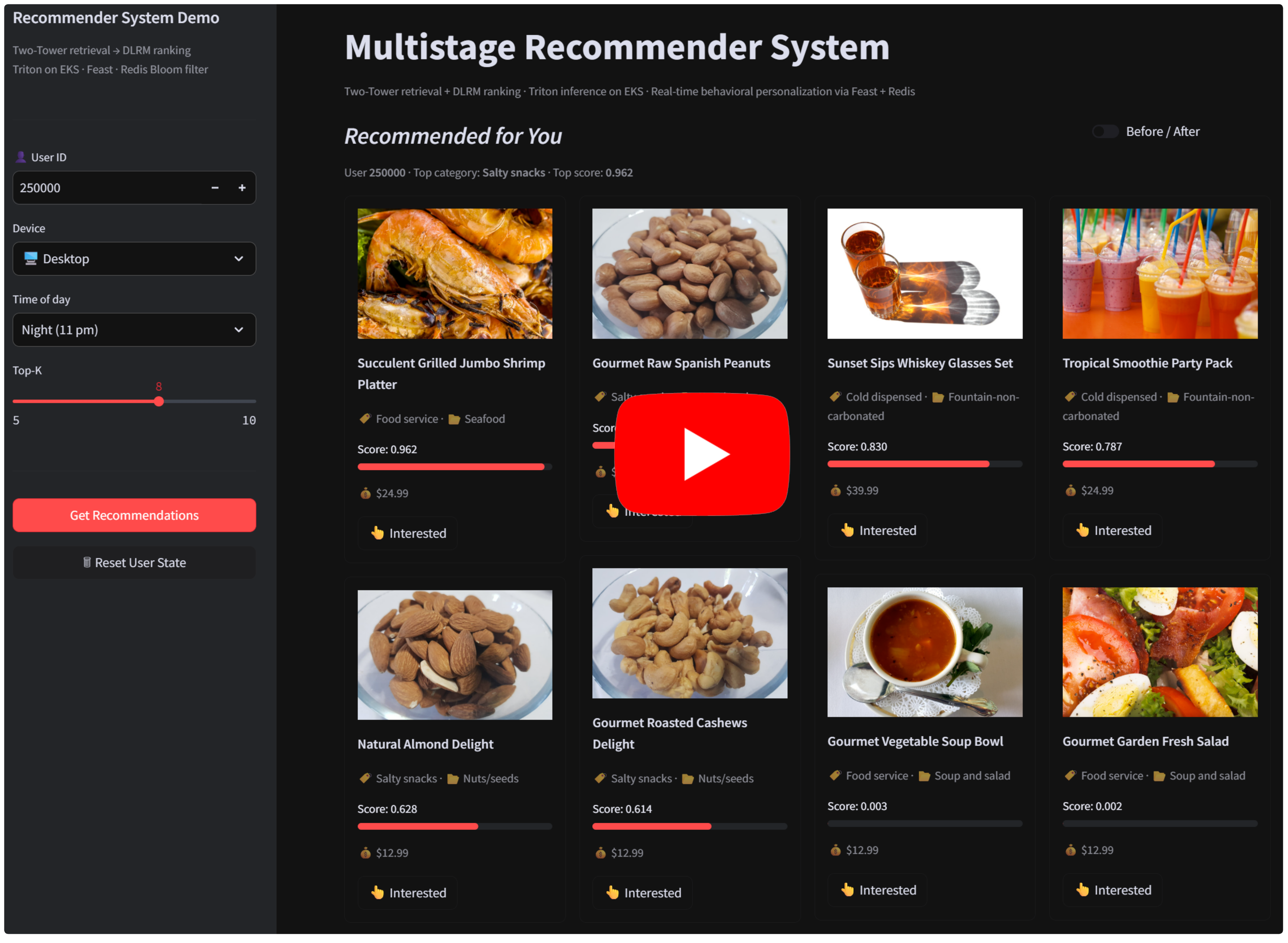
Interactive Demo
The demo shows recommendations adapting to changing user preferences in near real time, using the online feature update path above to refresh user features as new interactions are generated. Click the image to view the demo.
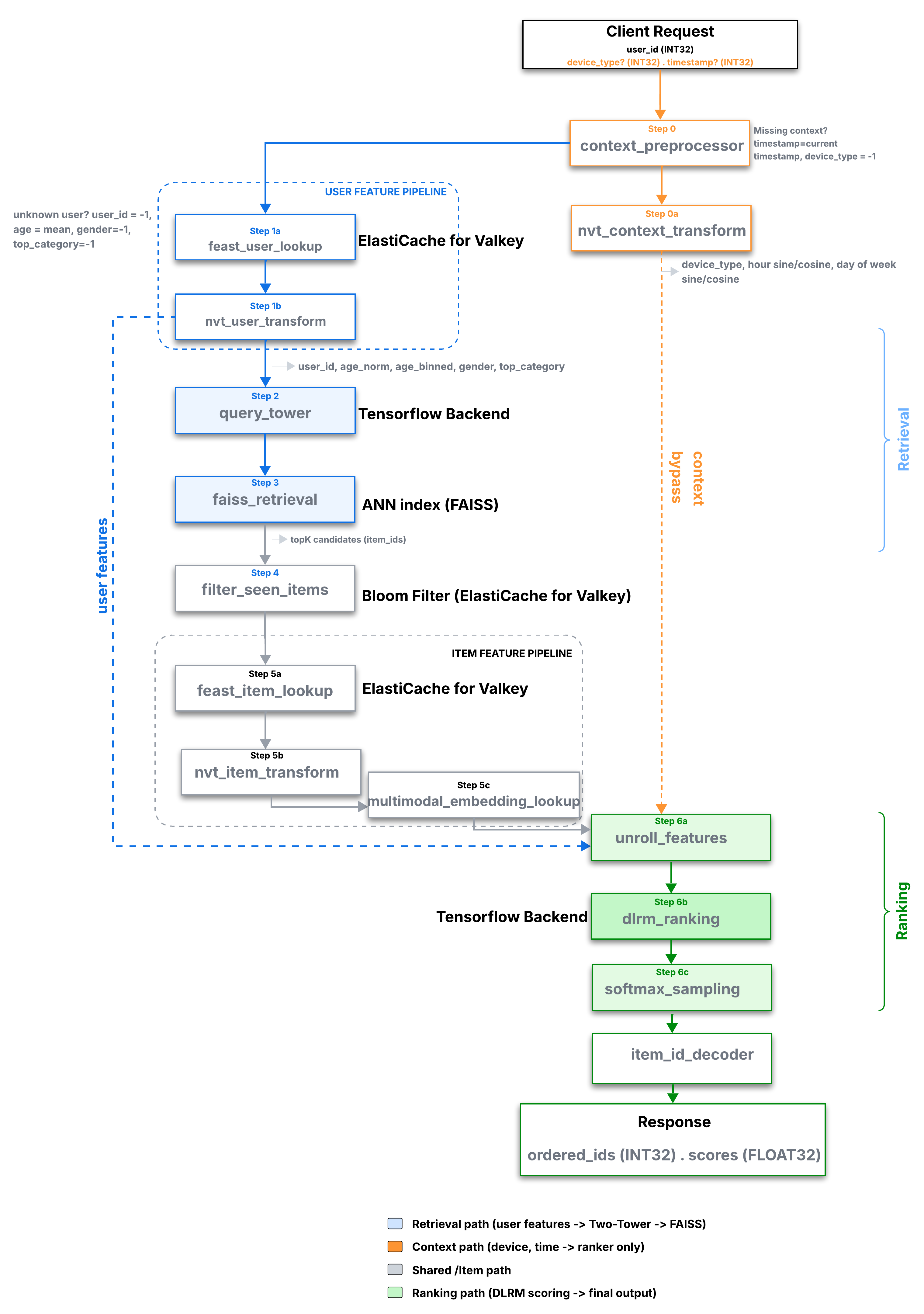
Triton Serving Ensemble
A single client request flows through a Triton ensemble including context preprocessing, Feast-backed user lookup, NVTabular transforms, Two-Tower retrieval with FAISS, Bloom-filter seen-item removal, item feature lookup, DLRM ranking, and final softmax sampling.
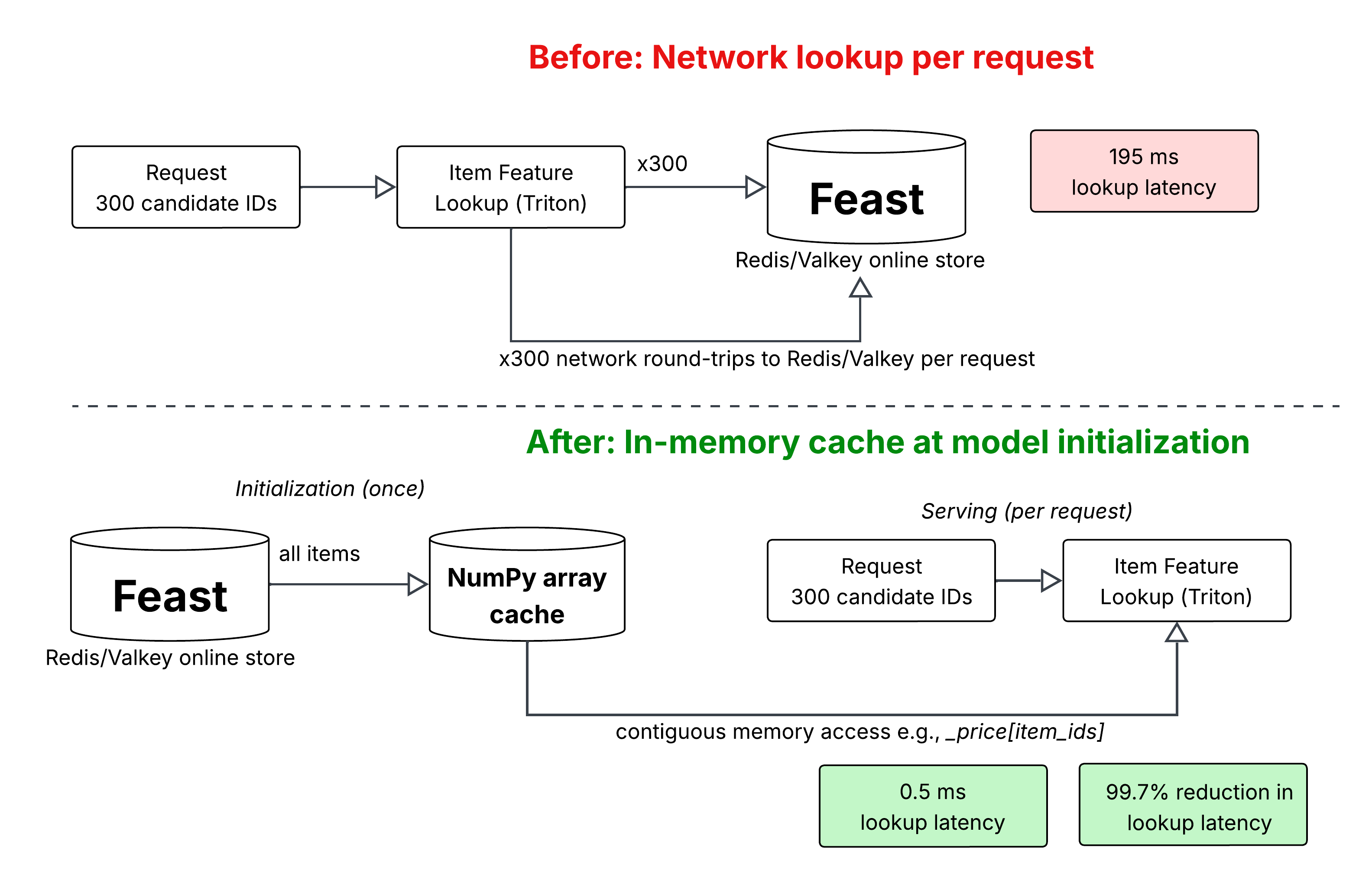
Feature Caching Optimization
Loading item features into an in-memory NumPy cache at model initialization reduced lookup latency from 195 ms to 0.5 ms, cut end-to-end latency by 54% and improved throughput by 310%.
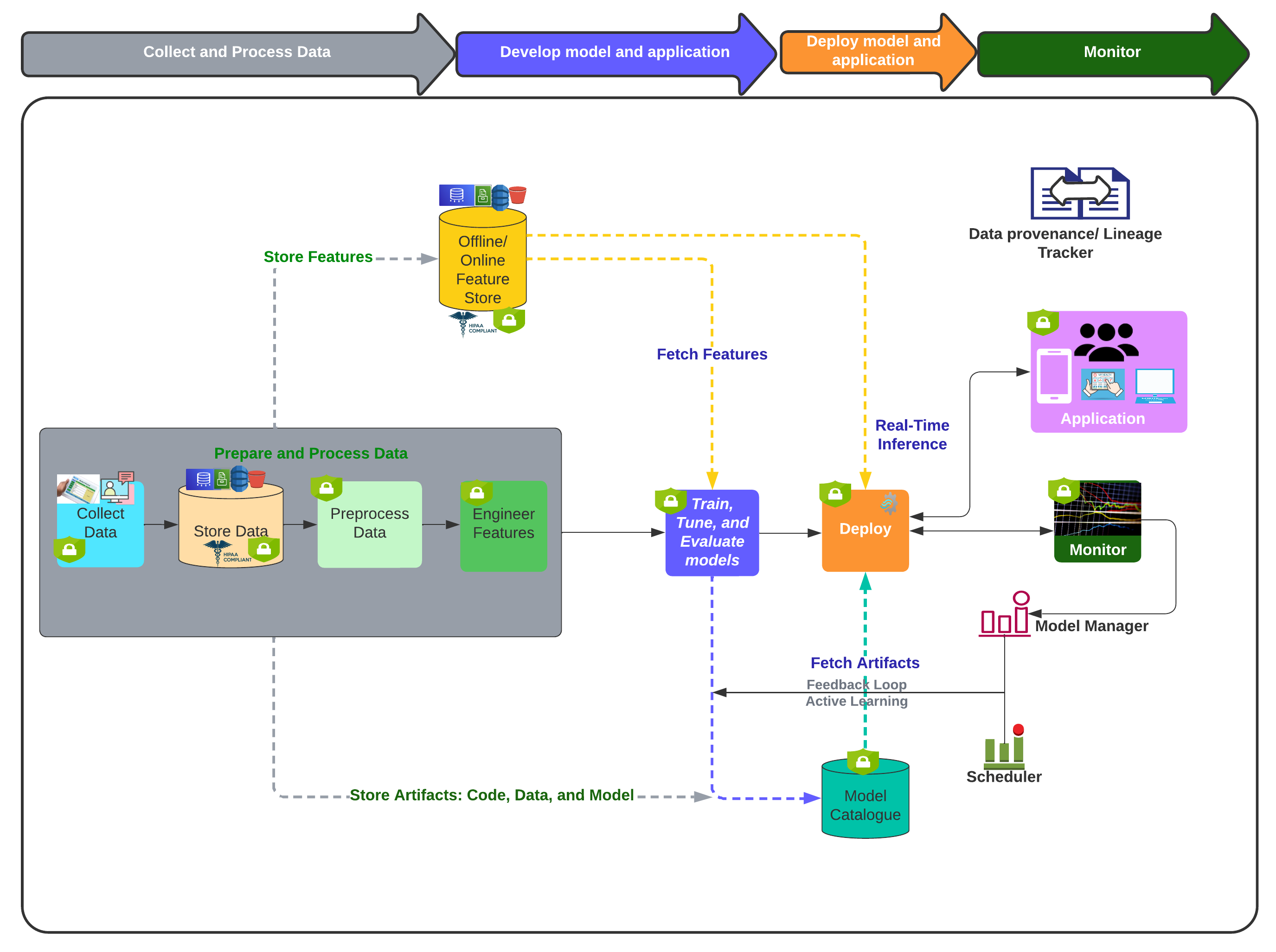
Training, Deployment, and Monitoring
The MLOps flow keeps training and serving on Amazon EKS: Kubeflow prepares data and models, artifacts are persisted to Amazon EFS, NVIDIA Triton Inference Server serves the 14-model ensemble, and Prometheus/Grafana track utilization, throughput, and latency for capacity planning.
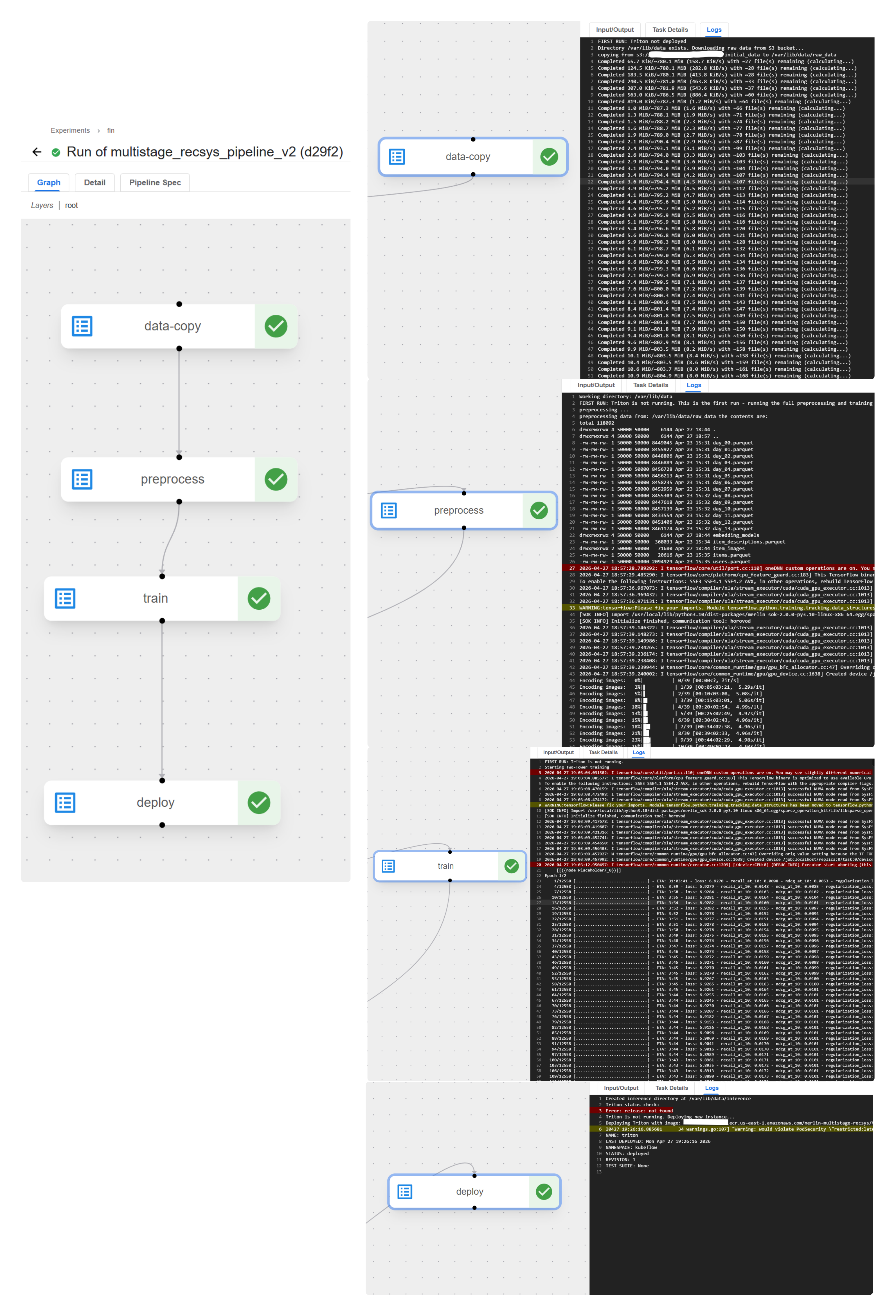
Initial Pipeline Run
The initial run builds the system from scratch. This includes the data preprocessing, feature store setup, Two-Tower and Deep Learning Recommendation Model training, ANN index setup, and Triton Server deployment.
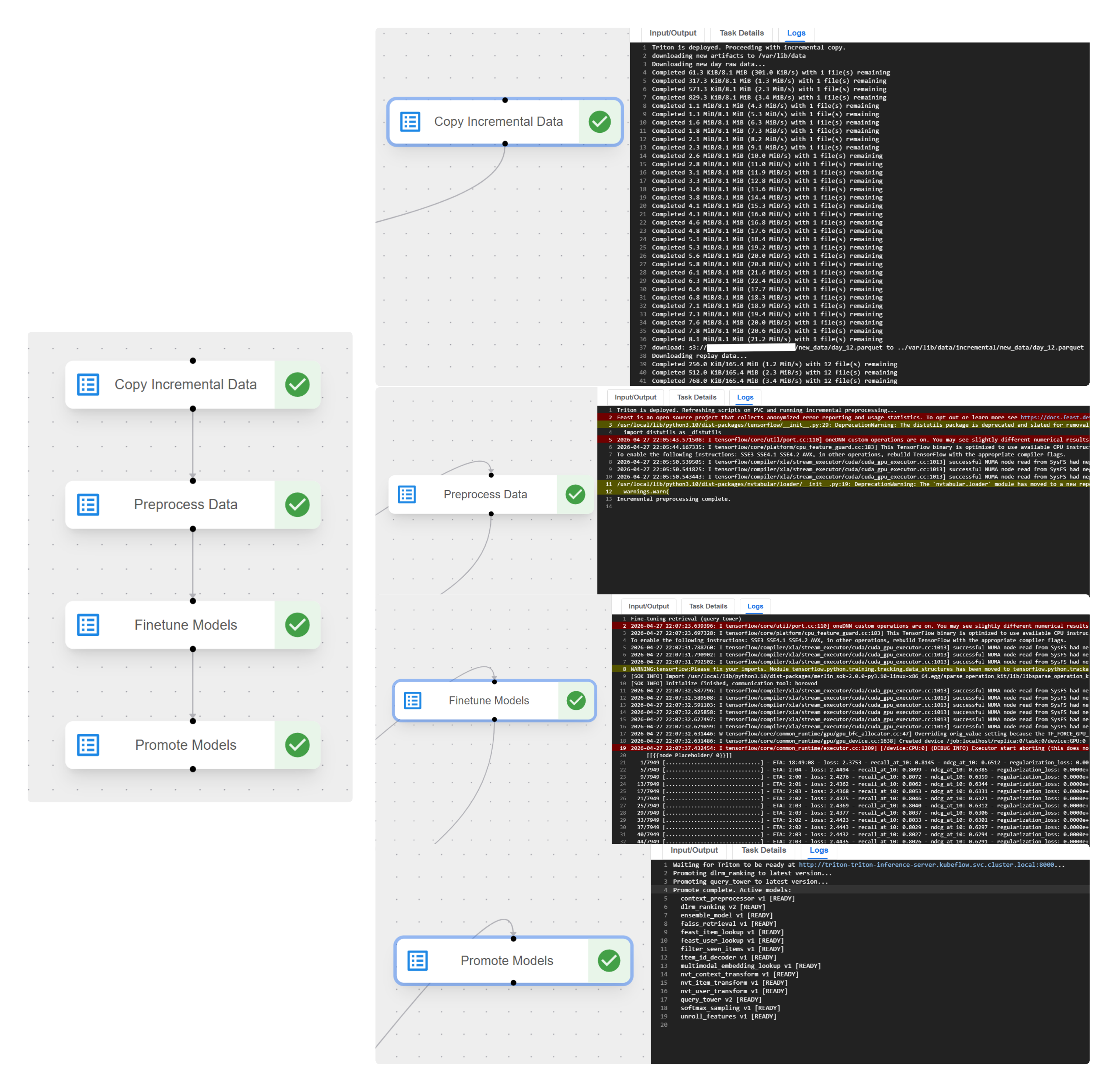
Incremental Pipeline Run
The incremental run updates the system without rebuilding everything from scratch. The Two-Tower is finetuned with the candidate encoder frozen, so only the query tower is updated. The ranker is finetuned with all layers trainable. Training uses recent data and some historical data for stability. The fine-tuned models are deployed to the server and Triton picks them up.
For the full implementation details, architecture decisions, and deployment notes, see the TDS article, Medium article, demo, or source code linked above.
Tools: Amazon EKS, NVIDIA Merlin, NVIDIA Triton, Feast, FAISS, Kubeflow, Redis/Valkey, CLIP, Sentence-BERT